
Controllable image synthesis with user scribbles has gained huge public interest with the recent advent of text-conditioned latent diffusion models. The user scribbles control the color composition while the text prompt provides control over the overall image semantics. However, we find that prior works suffer from an intrinsic domain shift problem wherein the generated outputs often lack details and resemble simplistic representations of the target domain. In this paper, we propose a novel guided image synthesis framework, which addresses this problem by modeling the output image as the solution of a constrained optimization problem. We show that while computing an exact solution to the optimization is infeasible, an approximation of the same can be achieved while just requiring a single pass of the reverse diffusion process. Additionally, we show that by simply defining a cross-attention based correspondence between the input text tokens and the user stroke-painting, the user is also able to control the semantics of different painted regions without requiring any conditional training or finetuning. Human user study results show that the proposed approach outperforms the previous state-of-the-art by over 85.32% on the overall user satisfaction scores.
We propose a diffusion-based guided image synthesis framework which models the output image as the solution
of a constrained optimization problem. Given a reference painting y, the constrained optimization (a)
is posed so as to find a solution x with two constraints: 1) upon painting x with an autonomous painting
function f we should recover a painting f(x) which is similar to reference painting y, and, 2) the output x should lie in the target
data subspace defined by the text prompt (
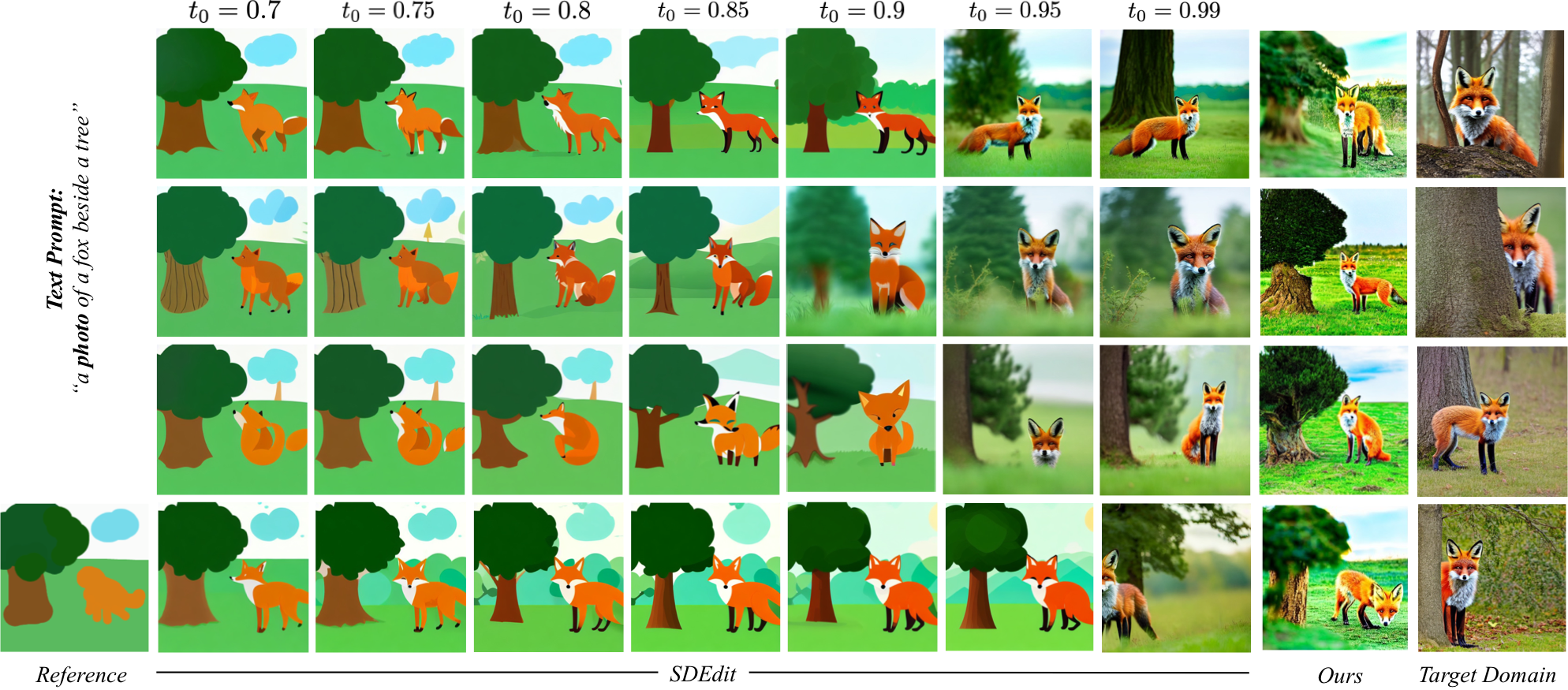
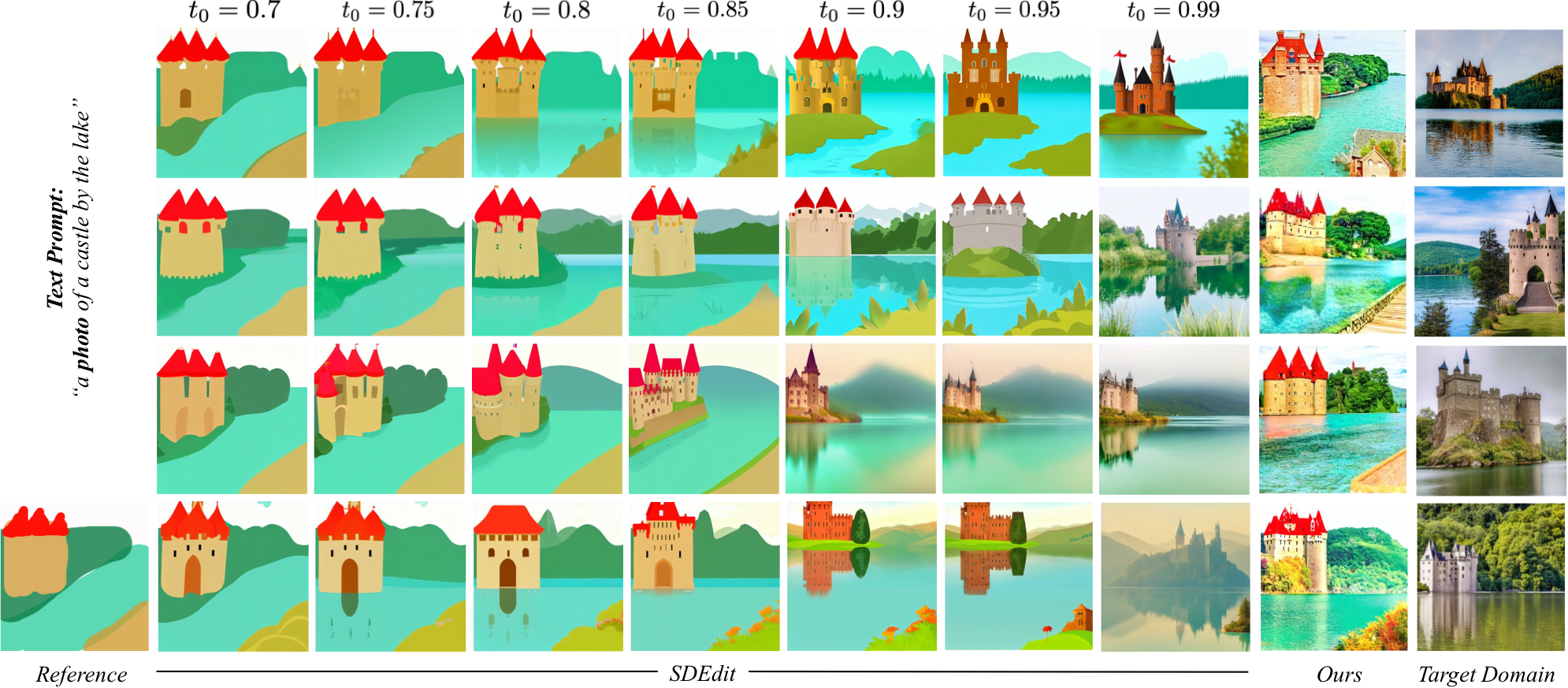
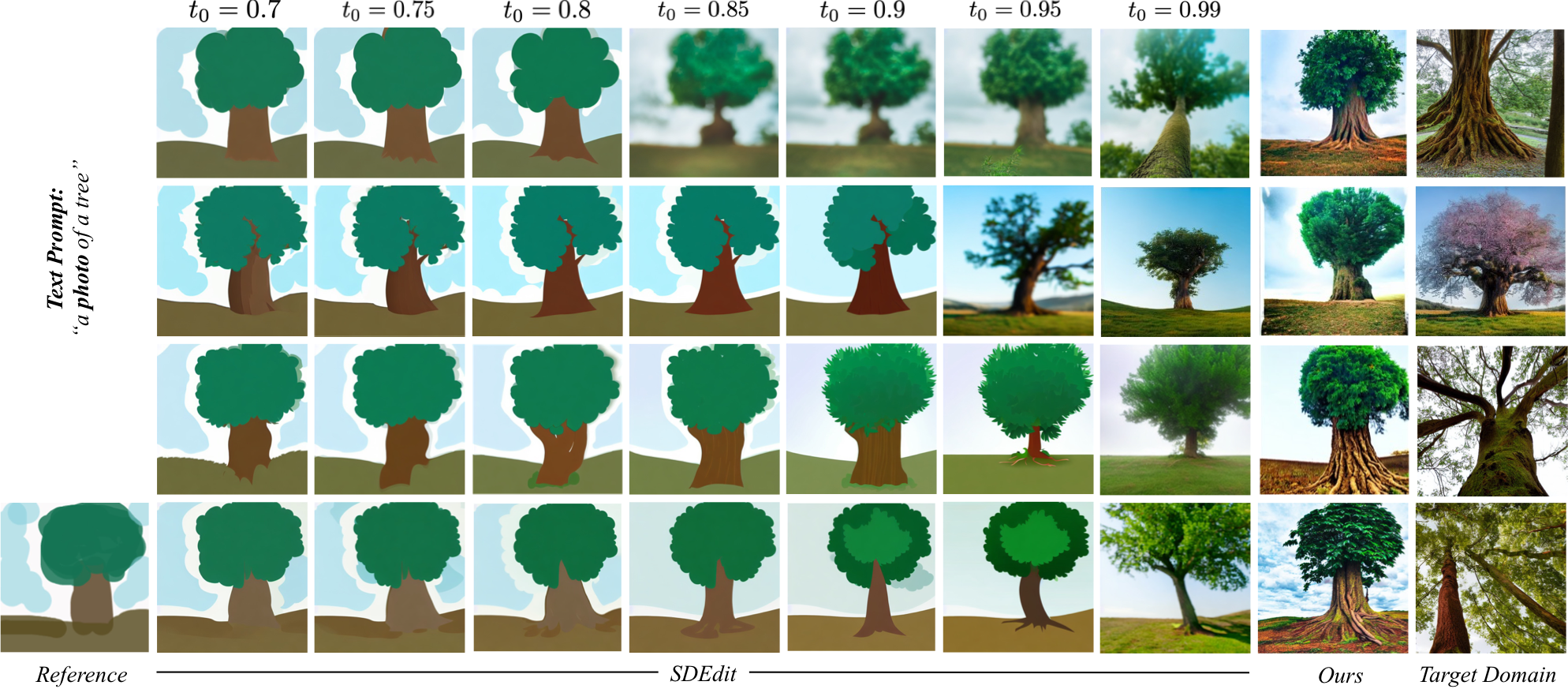
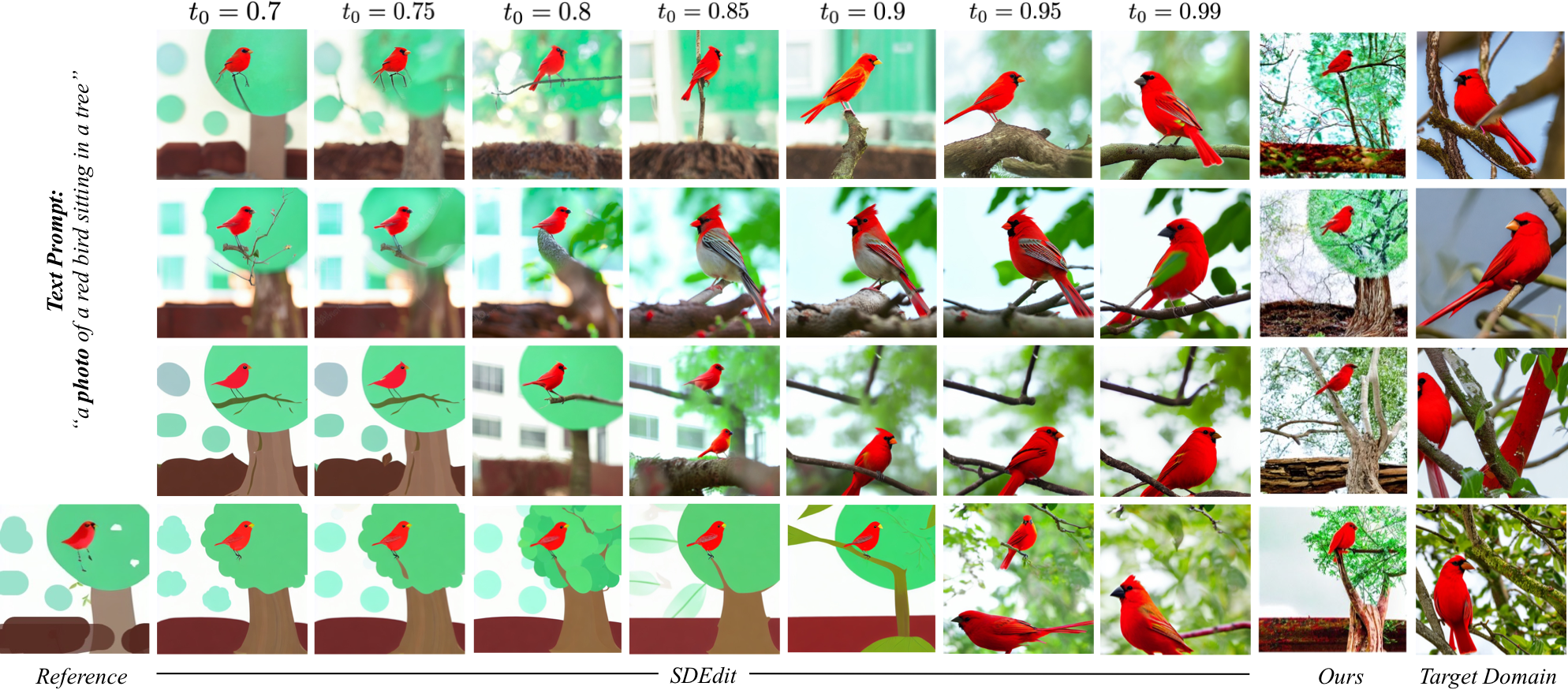
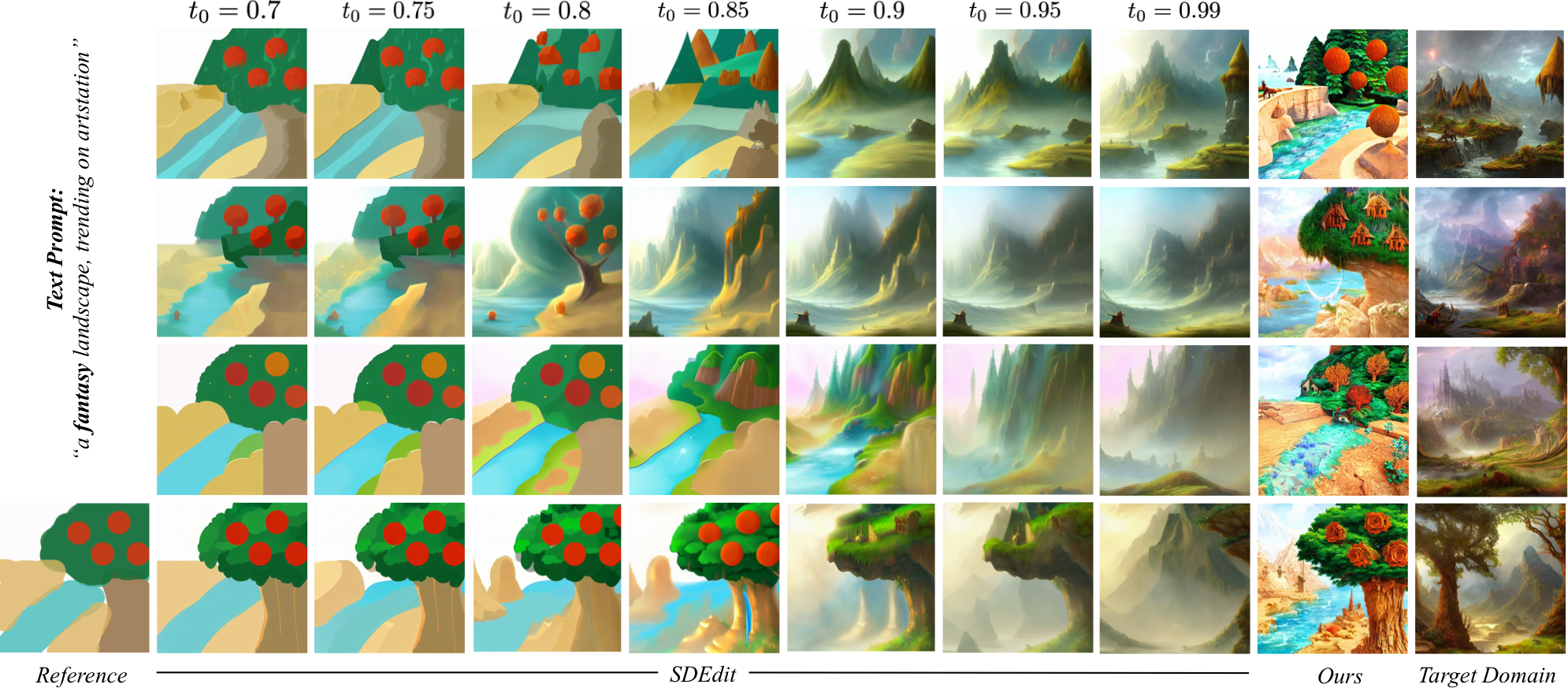
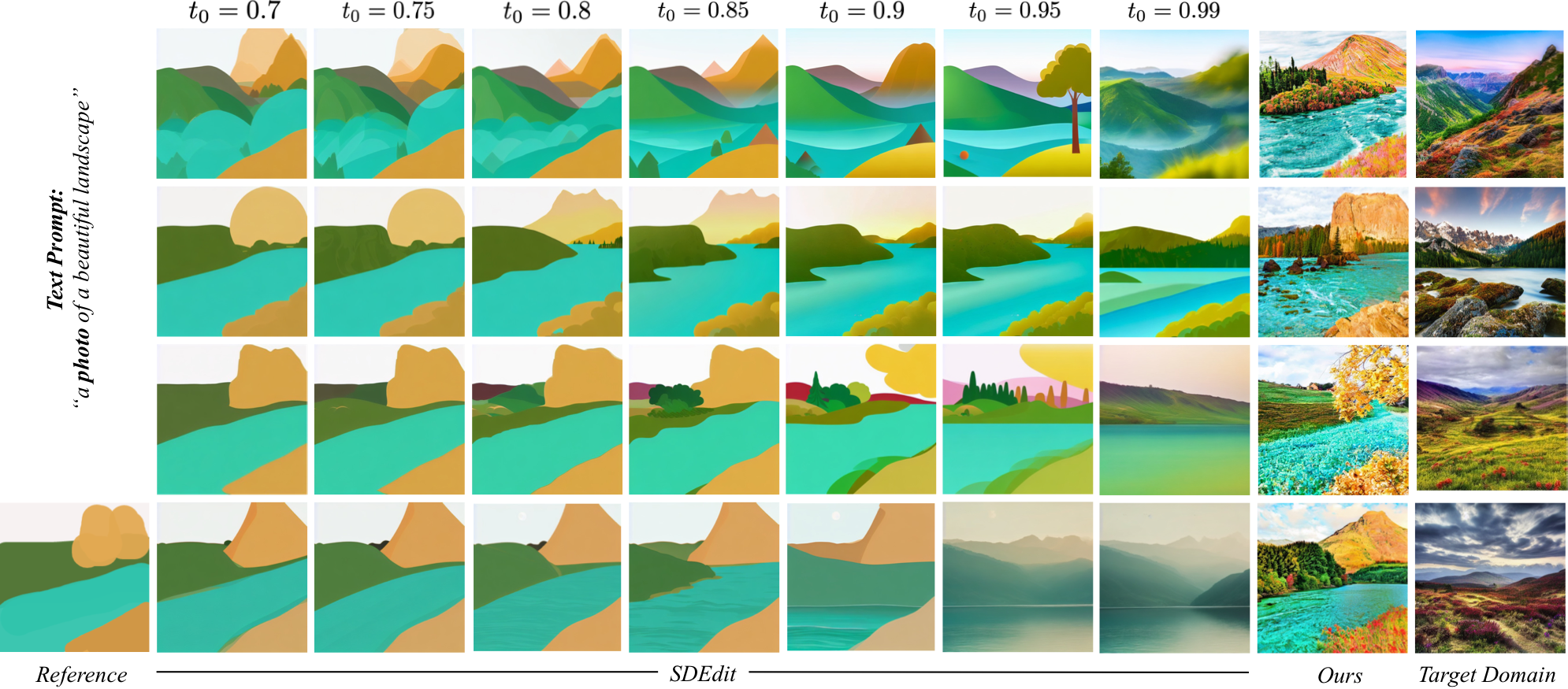
Comparison with prior works. As compared to prior works, our method provides a more practical approach for improving output realism (with respect to the target domain) while still maintaining the faithfulness with the reference painting.


More Results. Our approach allows the user to easily generate realistic image outputs across a range of data modalities.



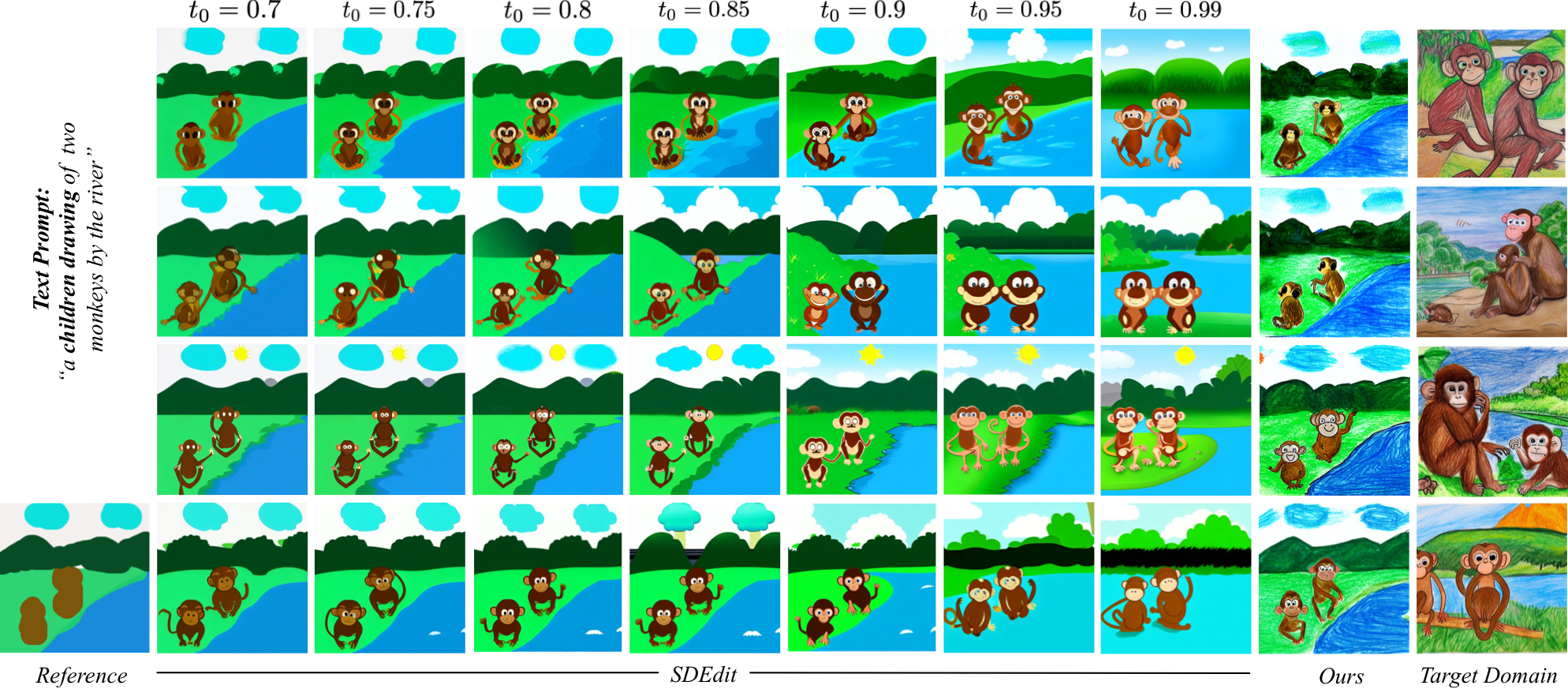
While performing guided image synthesis with coarse user-scribbles,
the semantics of different painted regions are inferred in an implicit manner. For instance, in following figure, we note that for different outputs,
the blue region can be inferred as a river, waterfall, or a valley. Also note that some painting regions might be entirely omitted (e.g., the brown strokes for the hut),
if the model does not understand that the corresponding strokes indicate a distinct semantic entity.

We show that by simply defining a cross-attention based corrrespondence between input text-tokens and reference painting, the user can control the semantics of different painting regions without needing any additonal training or finetuning.

As shown in above, we find that the proposed approach allows for a high level of semantic control (both color composition and fine-grain semantics) over the output image attributes, while still maintaining the realism with respect to the target domain. Thus a natural question arises: Can we use the proposed approach to generate realistic photos with out-of-distribution text prompts?
As shown below, we observe that both success and failure cases exist for out-of-distribution prompts. For instance, while the model was able to generate "realistic photos of cats with six legs"
(note that for the same inputs prior works either
generate faithful but cartoon-like outputs, or, simply generate regular cats),
it shows poor performance while generating "a photo of a rat chasing a lion".


A key component of the proposed method is to obtain an approximate solution for the constrained problem formulation (discussed above)
using simple gradient descent. In the following figure, we visualize the variation in generated outputs as the number of gradient descent steps used for
performing the optimization are increased.

As shown above, we find that for N=0, the generated outputs are sampled randomly from the subspace of outputs conditioned only on the text.
As the number of gradient-descent steps increase, the model converges to a subset of solutions
within the target subspace (conditioned only on text-prompt) which exhibit higher faithfulness with
the provided reference painting. Please note that this behaviour is in contrast with prior works like SDEdit,
wherein the increase in faithfulness to the reference is corresponded with a decrease in the realism of
the generated outputs.
@inproceedings{singh2023high,
title={High-Fidelity Guided Image Synthesis With Latent Diffusion Models},
author={Singh, Jaskirat and Gould, Stephen and Zheng, Liang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5997--6006},
year={2023}
}