







The field of text-conditioned image generation has made unparalleled progress with the recent advent of latent diffusion models. While remarkable, as the complexity of given text input increases, the state-of-the-art diffusion models may still fail in generating images which accurately convey the semantics of the given prompt. Furthermore, it has been observed that such misalignments are often left undetected by pretrained multi-modal models such as CLIP.
To address these problems, in this paper we explore a simple yet effective decompositional approach towards both evaluation and improvement of text-to-image alignment. In particular, we first introduce a Decompositional-Alignment-Score which given a complex prompt decomposes it into a set of disjoint assertions. The alignment of each assertion with generated images is then measured using a VQA model. Finally, alignment scores for different assertions are combined aposteriori to give the final text-to-image alignment score. Experimental analysis reveals that the proposed alignment metric shows significantly higher correlation with human ratings as opposed to traditional CLIP, BLIP scores.
Furthermore, we also find that the assertion level alignment scores provide a useful feedback which can then be used in a simple iterative procedure to gradually increase the expressivity of different assertions in the final image outputs. Human user studies indicate that the proposed approach surpasses previous state-of-the-art by 8.7% in overall text-to-image alignment accuracy.
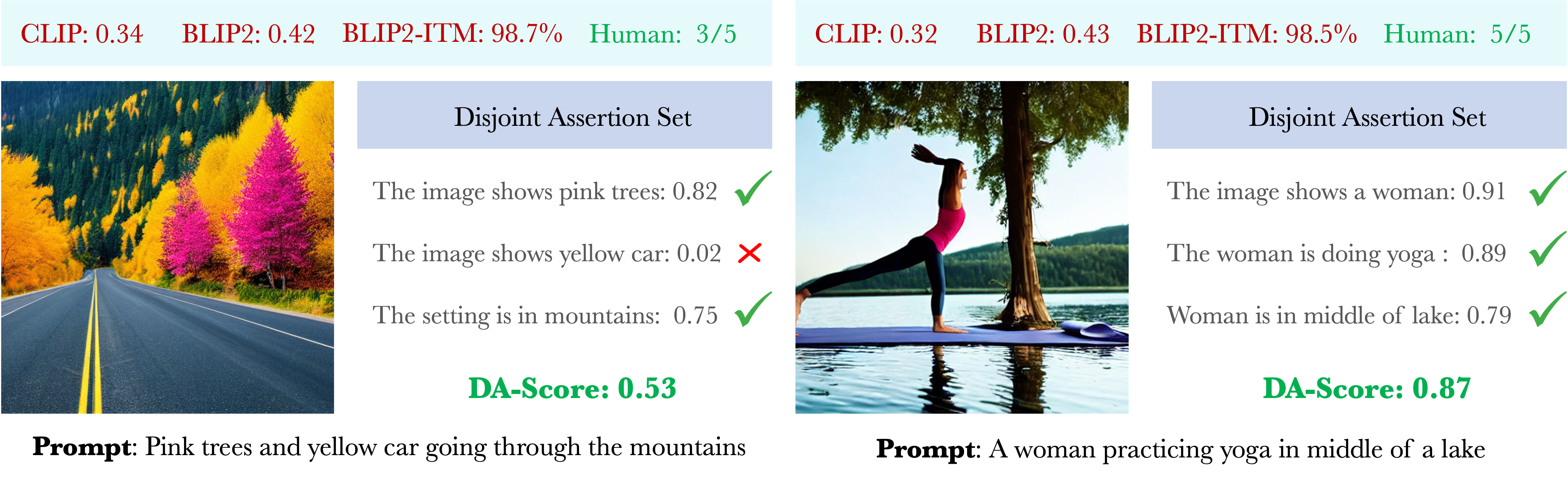
Decompositional Alignment Score: Traditional methods for evaluating text-to-image alignment, for example, CLIP1, BLIP-22 and BLIP2-ITM (which provides a binary image-text matching score between 0 and 1) often fail to distinguish between good (right) and bad (left) image outputs and can give high scores even if the generated image is not an accurate match for input prompt (missing yellow car). In contrast, by breaking down the prompt into a set of disjoint assertions and then evaluating their alignment with the generated image using a VQA model2, the proposed Decompositional-Alignment Score (DA-score) shows much better correlation with human ratings.
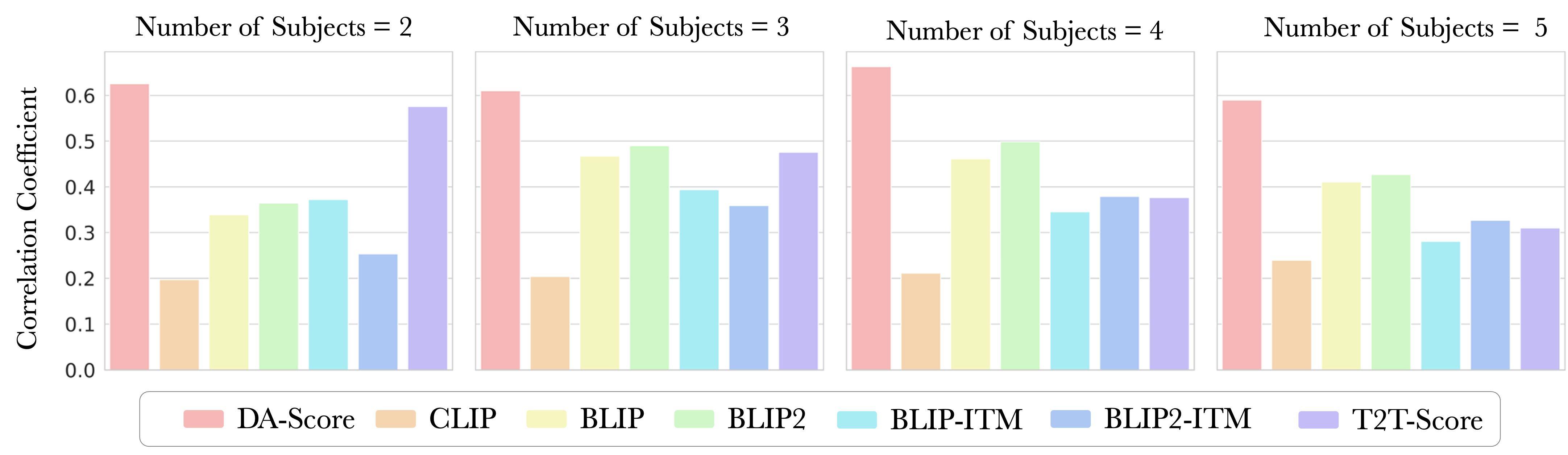
Method comparisons w.r.t correlation with human ratings:
We compare the correlation of different text-to-image alignment scores with those obtained from human subjects, as the number of subjects in the input prompt is varied.
We observe that the proposed alignment score (DA-score) provides a better match for human-ratings over traditional text-to-image alignment scores like CLIP, BLIP and BLIP2.
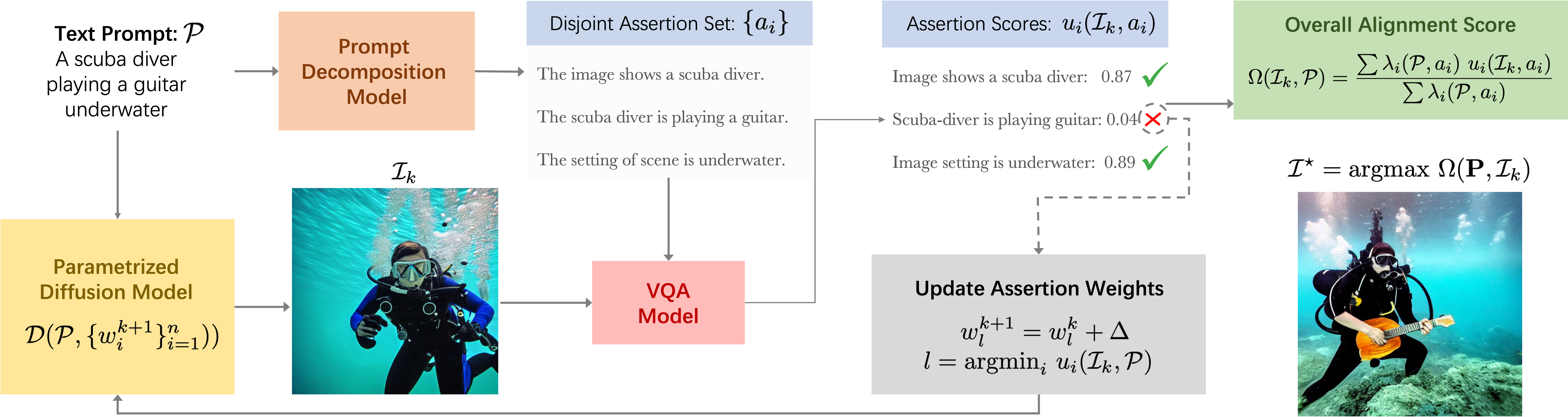
Method Overview:
Given a text prompt P and an initially generated output I, we first generate a set of disjoint assertions ai regarding the content of the caption. The alignment of the output image I with each of these assertions is then calculated using a VQA model. Finally, we use the assertion-based-alignment scores ui(I,P) as feedback to increase the weightage wi (of the assertion with least alignment score) in a parameterized diffusion model formulation. This process can then be performed in an iterative manner to gradually improve the quality of the generated outputs until a desirable threshold for the overall alignment score Omega(Ik,P) is reached.
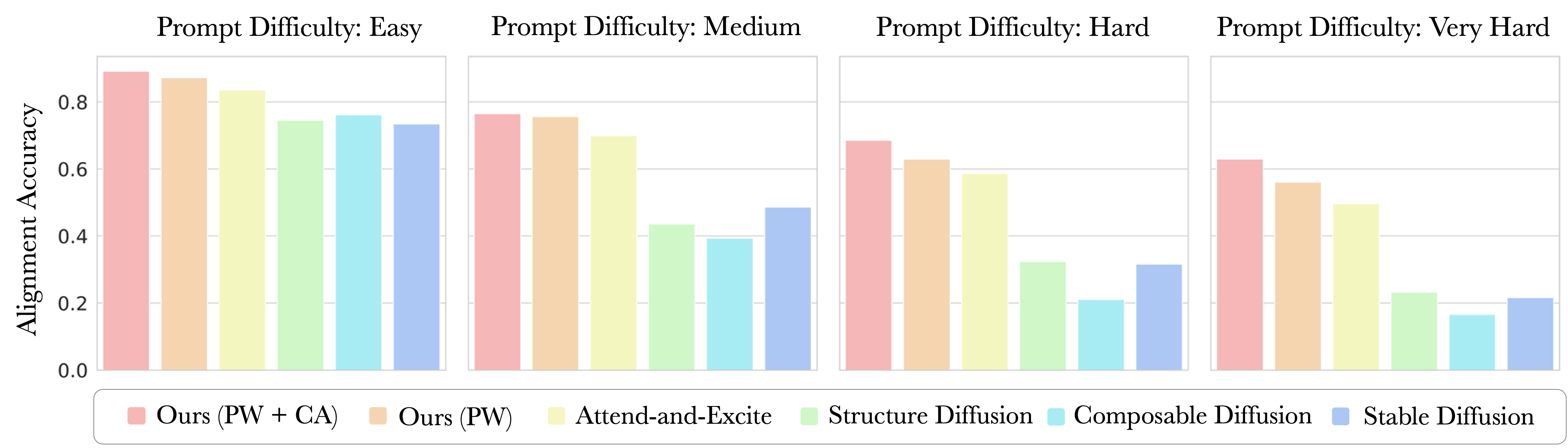
Variation of alignment accuracy with prompt difficulty. We observe that while the accuracy of all methods decreases with increasing prompt difficulty, the proposed iterative refinement approach consistently performs better than prior works.
Eval-and-Refine is Model Agnostic. Eval-and-Refine provides a simple "model-agnostic" approach for improving T2I performance across a range of T2I generation models.


Results on SDXL. Eval-and-Refine with prompt-weighting (PW) can also allow for better T2I generation with the recently proposed SDXL model.

@inproceedings{singh2023divide,
title={Divide, Evaluate, and Refine: Evaluating and Improving Text-to-Image Alignment with Iterative VQA Feedback},
author={Singh, Jaskirat and Zheng, Liang},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}